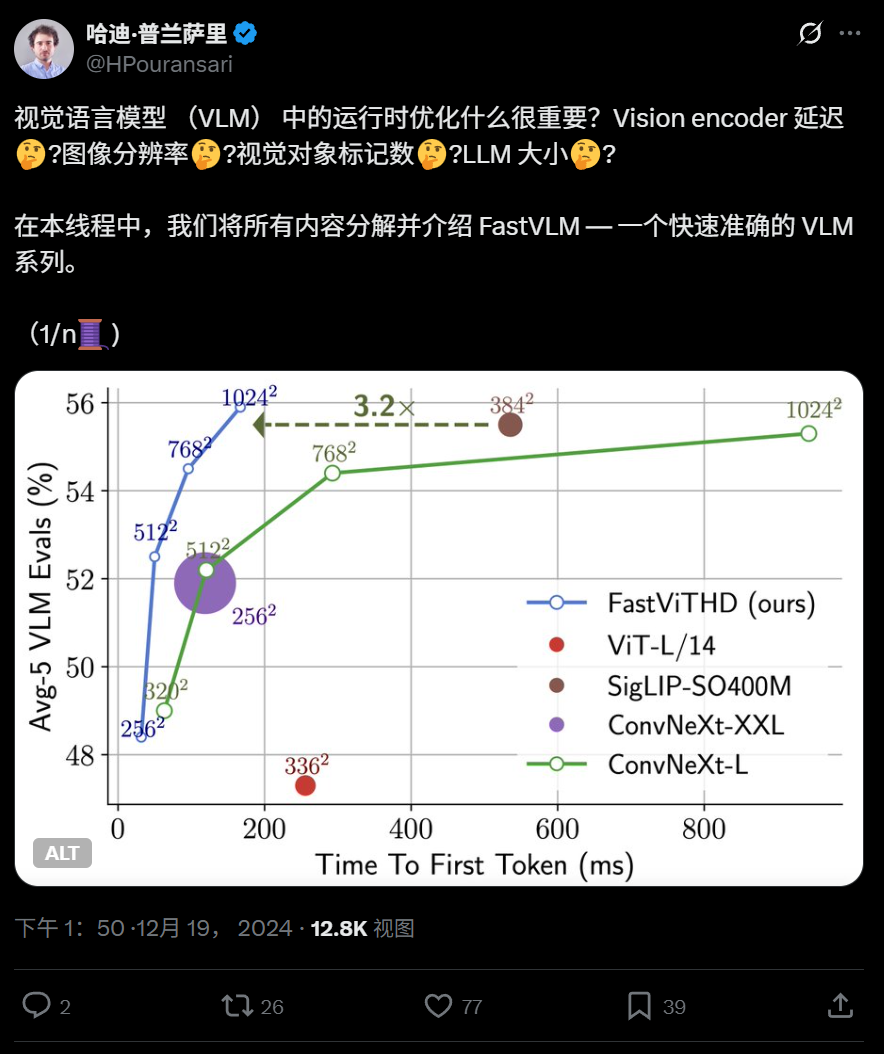
 FastVLM-让Apple手机具有非常快速的视觉理解功能。当您使用iPhone拍照并问AI时:“这是什么?”时,它背后的FastVLM模型是悄悄地 - 模型。最近,Apple开设了一个出色的视觉语言模型的来源,该模型可以直接在iPhone -fastvlm(快速视觉语言模型)上运行。代码链接:https://github.com/apple/ml-tastvlm代码存储库包括基于MLX框架的iOS/macOS演示的应用程序,该框架优化了Apple设备上的操作性性能。看到这个演示,是反应速度非常“快速”!这就是使FastVLM与众不同的原因。与传统模型相比,FASTVLM模型着重于解决两个主要卷和速度问题。这比类似的型号快,偏高的输出速度速度高85倍。该模型引入了一个新的混合视觉编码器FastVithD,该编码器结合了卷积层和变压器模块。结合多尺度合并和唐萨姆固定技术,图像处理所需的“视觉令牌”的数量减少到非常低 - 比传统VIT的16倍,比FastVit少4倍。这极大地改善了AI和图像之间的用户体验,并以极高的速度和兼容性。 Ang Modelo ng fastvlm ay印地语lamang maaaring magamit magamit upang awtomatikongakabuo ng mga pahayag para sa Modelo,sagutin ang mga katanungan tungkol sa“ ano ang arn an ang larawang ito?” Madaling Inangkop SA MGA应用程序NG IOS/MAC生态系统,Lalo na ang Angkop para sa mga aparato sa gilid,MGA端端Na Mga aplikasyon ng ai在实时图形和任务方案下。当前,FASTVLM模型主要启动三个不同参数订单的版本:0.5B,1.5B和7B。每个版本都有两个重量的阶段:Stage2和Stage3,并且可以根据自己的需求选择用户。苹果团队详细详细介绍了e具体的技术细节和优化已发表论文的途径。纸张标题:FastVLM:视觉语言纸张地址的出色视觉句子模型:https://www.arxiv.org/abs/2412.13303视觉语言研究模型(VLMS)是一种可以同时了解图像和文本信息的多模型。 VLM通常通过投影层(也已知的BSOME连接模块)将视觉令牌从预先的视觉主链网络转到预先进行的LLM。先前的研究探索了视觉脊柱网络和适配器。这三个组件LLM的训练技术和微调是常见的解码器结构。许多研究教导说,图像分辨率是影响VLM性能的主要因素,尤其是面对密集或密集的图形数据时。但是,改进图像分辨率也带来了许多挑战。首先,许多预先的视力编码器在设计时不支持高分辨率图像输入,因为它的意义远程降低效率。要解决这个问题,一个过程是继续预先对视觉脊柱进行训练,以使其适应高分辨率图像。其余的是图像平铺技术(例如狮身人面像,S2和Anyres)将图像sa除以许多子区域,而视觉脊柱将分别处理每个子区域。这种类型的方法特别适合基于视觉变压器(VIT)的模型体系结构,因为VIT通常不支持变量输入分辨率。另一个挑战来自计算高分辨率高分辨率时计算运行时的成本。无论是对高分辨率的单一概念还是对较低分辨率的多重理解(即使用切口方法),视觉令牌的形成都有很大的延迟。此外,具有高分辨率的图像本身会产生更多的令牌,从而进一步增加了LLM预填充时间(即预填充时间,即LLM促进的时间TS向前计算在包括VisualStoken在内的所有上下文令牌上),从而扩大了一般的初始输出时间(TTTFT,TTFT),即视觉编码器延迟和语言时间预填充的总和。这项研究将VLM设备的部署作为驱动力,并从运行时效率的前景中进行了系统的设计和培训研究。我们专注于改善图像分辨率对优化空间的影响,目的是提高权衡的准确性 - 延迟,其中延迟包括视觉编码器的前景时间和LLM的预填充时间。通过在各种LLM量表和图像分辨率上进行大量实验,研究人员证明,在特定的视觉脊柱条件下,可以建立帕累托的最佳条件,以证明最佳准确度可以通过在有限的运行频率预算(TTTFT)中纳入各种图像分辨率和语言模型来实现。研究人员有FIRT探索了FastVit(Mobileclip预先获得的杂种卷积架构架构)作为VLM视觉脊柱的潜力。实验表明,这种混合脊柱在开发视觉令牌中的速度比标准VIT模型快四倍以上,同时还基于多规模的视觉特征,可以实现VLM提高的总体精度。但是,如果目标是主要的高分辨率VLM(而不是简单地关注作为MobileClip的一代的嵌入),则该体系结构仍将有进一步优化的空间。因此,研究人员提出了一种新的混合视觉编码器FastVithD,旨在在处理高分辨率图像时MAVLM效率提高。它被用作脊柱网络,通过微调视觉说明来获取FASTVLM。 FASTVLM显着优于基于VIT,卷积元素编码器的VLM程序,并且我们先前建议的杂种结构迅速地以精确范围ACY和延迟权衡。特别是,与以最高分辨率(1152×1152)运行的Llava-onevision相比,FASTVLM在0.5B LLM的相同条件下实现了可比的性能,而TTFT的速度更快85倍,而视觉编码器尺度较小3.4倍。 Model的建筑研究人员首先探索了将FastVit Hybrid Vision编码器申请到VLM的潜力,然后提出了一些建筑障碍技术,以提高VLM活动的一般性能。在此基础上,研究人员建议FastVit-HD-A现代混合视觉编码为高分辨率处理活动定制,结合了高效率和高性能。通过大量的消融实验,研究人员与原始的FastVit和在各种大规模语言(LLM)体系结构和各种图像分辨率条件下的原始FASTVIT和现有方法相比,已充分证明了FastVit-HD性能的显着优势。如图2所示,显示了FastVLM和FastVit-HD的一般体系结构。所有实验都使用与LLAVA-1.5相同的训练调整,除非指定,否则使用Vicuna 7b作为语言解码器。 FastVit是一种典型的VLM(如LLAVA),包含三个震惊:图像编码器,视觉语言投影仪和大型语言模型(LLM)。 VLM系统的性能和操作效率高度取决于其视觉脊柱。高分辨率图像的编码对于各种VLM基准活动中的良好性能尤其重要,尤其是在密集文本任务中。因此,支持可扩展分辨率的视觉编码对于VLM尤为重要。研究人员发现,混合视觉编码器(由卷积层和变压器块组成)是VLM的非常微妙的选择,以及支持民间分辨率缩放的对流组件,而变压器模块进一步捕获了LLM的高质量视觉图表。一个Periment用于在剪辑中预先进行交易的混合视觉编码器 - iLeclip电影建议的MCI2编码器。编码器具有3570万参数,以前在Datacompdr数据集中训练,并且该体系结构基于FastVit。本文将编码器称为“ fastvit”。但是,如表1所示,如果仅在预训练的分辨率剪辑(256×256)中使用FastVit,则VLM性能并不完美。 FastVit的主要优点是它在图像分辨率的缩放率方面的效率 - 与贴片大小为14的VIT体系结构相比,其生成的令牌数量低5.2倍。如此大的农作物令牌显着提高了VLM的工作效率,因为变压器解码器的预填充时间和第一个令牌(以前的时间)的输出时间大大降低了。当FastVit输入分辨率扩展到768×768时,构成其的视觉令牌的数量通常会以336×336的vit-l/14在336×336的分辨率中使用,但获得了更好的perfo许多VLM基准测试。尽管两个体系结构形成了相同数量的视觉令牌,但在诸如TextVQA和DOCVQA之类的密集文本活动中,这种性能差距尤为明显。此外,尽管在高分辨率下的代币数量仍然保持平坦,但FastVit的总时间仍然比良好的卷积模块短。 1。多尺度特征通常是卷积或混合动力,通常将计算过程分为4个阶段,每个阶段都包含一个降采样操作。 VLM系统通常使用倒数第二层输出功能,但是从网络的前几层获得的信息通常具有不同的晶粒。经济量表的特征的集成不仅可以提高模型的表达能力,而且可以增强倒数第二层中的高度语义信息。这种设计在发现对象时尤其普遍。研究人员对两个设计方案之间的消融进行了比较从不同阶段转换功能:含义池(AVGPooling)和2D深度卷积。如表2所示,深度段的使用具有更大的性能优势。除多尺度功能外,研究人员还进行了各种连接器设计尝试(请参阅其他材料)(有关详细信息,请参见其他材料)。模型结构对于使用层次骨架,例如Convnext和FastVit的架构特别有效。 FastVit-HD:引入上述改进后,FastVit的参数比VIT-L/14更小。它的表现出色,为8.7次。但是,这些Studys表明,扩大图像编码器的大小有助于增强功能。在混合体系结构中,同时在第3阶段和第4阶段(如维生素所使用的)中同时扩大自我意见层的数量和宽度是很常见的,但是我们发现,只有在FastVit上扩展这些层并不是最好的解决方案(请参见图3,请参见图3。细节),这比Convnext-l速度差。为了防止执行额外的自我刺激层的负担,研究人员在结构中增加了一个额外的阶段,并在此之前添加了一个下采样层。在这种结构中,由自我维修层处理的特征sizethe地图以1/32的比例(与1/16的常见混合模型(如维生素)(例如维生素)相比),MLP的最深层甚至由张量下降到1/64。对于计算密集的LLM解码器,该设计大大降低了图像图像的潜伏期,同时将视觉令牌减少到4倍,从而大大减少了第一个输出(TTFT)输出时间。研究人员将FastVit-HD架构命名为。 FastVit-HD由五个阶段组成。转装器模块在前三个阶段使用,并且在最后两个阶段使用多头自我意识模块。每个阶段的深度设置为[2、12、24、4、2],大小肠道的是[96,192,384,768,1536]。 Convffn模块的MLP扩展比率为4.0。参数的总卷为1251m,是Mobileclip家族中最大的FastVit变体的3.5倍,但它比大多数VIT的主要建筑小。研究人员使用了剪辑的预训练设置,该设置已通过Datacomp-DR-1B进行了预训练,然后在模型上进行了FASTVLM培训。如表3所示,尽管FastVit-HD参数值比VIT-L/14小的2.4倍,并且运行速度快6.9倍,但38个多模式零样本活动的平均性能是可比的。与专门为VLM构建的另一个混合维生素模型相比,FastVit-HD参数体积小于2.7倍,识别速度速度更快5.6倍,并且性能性能更好。该表将多模式FastVit-HD的多模式工作性能与其他经过剪辑训练的层次型骨干网络(例如Convernext-l和XXLAT)的llava-1.5培训结束。虽然FastVit-HD参数卷仅为Convnext-XXL的1/6.8,速度最多为3.3倍,其性能仍然可比。 2。VLM语言解码器的视觉编码器ATSYGENGY,性能和延迟之间的权衡受许多因素的影响。一方面,其整体性能取决于:(1)输入图像的分辨率,(2)输出和质量输出量以及(3)LLM建模功能。另一方面,它的总延迟(尤其是令牌,TTFT的第一次)包括延迟图像编码和LLM预填充时间,这受令牌和LLM标度的数量的影响。由于VLM优化空间的高复杂性,有关视觉编码器繁殖的任何结论都应证明有许多与LLM配对的输入分辨率集。与从经验的角度相比,INWE比较了FastVit-HD的可靠性。研究人员尝试了三个LLM(QWEN2-0.5B/1.5B/7B),并进行了Llava-1.5培训和视觉在各种输入分辨率中调整说明,然后在许多活动中审查结果。结果如图4所示。首先,图4中的帕累托最佳曲线表明,与最佳性能相对应的encoder-llm的组合在固定预算条件下是动态的(例如运行时TTFT)。例如,不建议将高分辨率图像输入配备小型LLM,因为小型模型无法有效使用许多令牌。同时,由于视觉编码延迟,TTFT将增加(有关详细信息,请参见图5)。其次,FastVit-HD Traversal(分辨率,LLM)所形成的最佳帕累托曲线明显优于FastVit-在固定延迟预算下,平均性能改善超过2.5点;在同一目标时机下,它可以加速约3次。值得注意的是,先前的结论表明,基于FastVit的VLM超过了VIT-HD,并且FastVit-HD在t上的t剂量更大明显改善他的基础。 3。调整输入分辨率时静态和动态输入分辨率,有两种技术:(1)直接更改模型的输入分辨率; (2)将图像分为图块块,然后将模型输入设置为瓷砖大小。后者属于“ Anyres”方法,该方法主要用于使VIT处理高分辨率图像。但是,FastVit-HD是为高分辨率效率而设计的,因此我们对这两种方法的效率进行了比较审查。图6显示,如果将输入分辨率直接设置为目标分辨率,则VLM已获得准确性和延迟之间的最佳平衡。动态输入仅在输入分辨率很高(例如1536×1536)时显示出好处,并且瓶颈主要显示在设备上的内存带宽中。使用动态方法时,瓷砖数量越小,可以实现更好的精度 - 性能延迟。以及Har的发展Dware和存储器带宽,FastVLM实现了增加的分辨率处理而无需瓷砖拆分将是一个可行的方向。 4。与代币修剪和下采样方法的比较研究人员更多地比较了FastVit-HD与各种输入分辨率以及经典的Pamperslow代币修剪。如表5所示,使用层次骨干网络的VLM明显优于基于各向同性体系结构的过程,并且在代币修剪的帮助下已经优化。 FastVit-HD可以在不使用修剪方法和仅使用低分辨率训练的情况下将视觉令牌的数量减少到只有16个,并且比最近的一些令牌修剪解决方案更好。有趣的是,尽管最先进的令牌修剪方法(如建议[7,28,29,80]),但总体性能在256×256的分辨率中不如FASTVIT-HD好。有关更多详细信息,请参阅原始论文。
FastVLM-让Apple手机具有非常快速的视觉理解功能。当您使用iPhone拍照并问AI时:“这是什么?”时,它背后的FastVLM模型是悄悄地 - 模型。最近,Apple开设了一个出色的视觉语言模型的来源,该模型可以直接在iPhone -fastvlm(快速视觉语言模型)上运行。代码链接:https://github.com/apple/ml-tastvlm代码存储库包括基于MLX框架的iOS/macOS演示的应用程序,该框架优化了Apple设备上的操作性性能。看到这个演示,是反应速度非常“快速”!这就是使FastVLM与众不同的原因。与传统模型相比,FASTVLM模型着重于解决两个主要卷和速度问题。这比类似的型号快,偏高的输出速度速度高85倍。该模型引入了一个新的混合视觉编码器FastVithD,该编码器结合了卷积层和变压器模块。结合多尺度合并和唐萨姆固定技术,图像处理所需的“视觉令牌”的数量减少到非常低 - 比传统VIT的16倍,比FastVit少4倍。这极大地改善了AI和图像之间的用户体验,并以极高的速度和兼容性。 Ang Modelo ng fastvlm ay印地语lamang maaaring magamit magamit upang awtomatikongakabuo ng mga pahayag para sa Modelo,sagutin ang mga katanungan tungkol sa“ ano ang arn an ang larawang ito?” Madaling Inangkop SA MGA应用程序NG IOS/MAC生态系统,Lalo na ang Angkop para sa mga aparato sa gilid,MGA端端Na Mga aplikasyon ng ai在实时图形和任务方案下。当前,FASTVLM模型主要启动三个不同参数订单的版本:0.5B,1.5B和7B。每个版本都有两个重量的阶段:Stage2和Stage3,并且可以根据自己的需求选择用户。苹果团队详细详细介绍了e具体的技术细节和优化已发表论文的途径。纸张标题:FastVLM:视觉语言纸张地址的出色视觉句子模型:https://www.arxiv.org/abs/2412.13303视觉语言研究模型(VLMS)是一种可以同时了解图像和文本信息的多模型。 VLM通常通过投影层(也已知的BSOME连接模块)将视觉令牌从预先的视觉主链网络转到预先进行的LLM。先前的研究探索了视觉脊柱网络和适配器。这三个组件LLM的训练技术和微调是常见的解码器结构。许多研究教导说,图像分辨率是影响VLM性能的主要因素,尤其是面对密集或密集的图形数据时。但是,改进图像分辨率也带来了许多挑战。首先,许多预先的视力编码器在设计时不支持高分辨率图像输入,因为它的意义远程降低效率。要解决这个问题,一个过程是继续预先对视觉脊柱进行训练,以使其适应高分辨率图像。其余的是图像平铺技术(例如狮身人面像,S2和Anyres)将图像sa除以许多子区域,而视觉脊柱将分别处理每个子区域。这种类型的方法特别适合基于视觉变压器(VIT)的模型体系结构,因为VIT通常不支持变量输入分辨率。另一个挑战来自计算高分辨率高分辨率时计算运行时的成本。无论是对高分辨率的单一概念还是对较低分辨率的多重理解(即使用切口方法),视觉令牌的形成都有很大的延迟。此外,具有高分辨率的图像本身会产生更多的令牌,从而进一步增加了LLM预填充时间(即预填充时间,即LLM促进的时间TS向前计算在包括VisualStoken在内的所有上下文令牌上),从而扩大了一般的初始输出时间(TTTFT,TTFT),即视觉编码器延迟和语言时间预填充的总和。这项研究将VLM设备的部署作为驱动力,并从运行时效率的前景中进行了系统的设计和培训研究。我们专注于改善图像分辨率对优化空间的影响,目的是提高权衡的准确性 - 延迟,其中延迟包括视觉编码器的前景时间和LLM的预填充时间。通过在各种LLM量表和图像分辨率上进行大量实验,研究人员证明,在特定的视觉脊柱条件下,可以建立帕累托的最佳条件,以证明最佳准确度可以通过在有限的运行频率预算(TTTFT)中纳入各种图像分辨率和语言模型来实现。研究人员有FIRT探索了FastVit(Mobileclip预先获得的杂种卷积架构架构)作为VLM视觉脊柱的潜力。实验表明,这种混合脊柱在开发视觉令牌中的速度比标准VIT模型快四倍以上,同时还基于多规模的视觉特征,可以实现VLM提高的总体精度。但是,如果目标是主要的高分辨率VLM(而不是简单地关注作为MobileClip的一代的嵌入),则该体系结构仍将有进一步优化的空间。因此,研究人员提出了一种新的混合视觉编码器FastVithD,旨在在处理高分辨率图像时MAVLM效率提高。它被用作脊柱网络,通过微调视觉说明来获取FASTVLM。 FASTVLM显着优于基于VIT,卷积元素编码器的VLM程序,并且我们先前建议的杂种结构迅速地以精确范围ACY和延迟权衡。特别是,与以最高分辨率(1152×1152)运行的Llava-onevision相比,FASTVLM在0.5B LLM的相同条件下实现了可比的性能,而TTFT的速度更快85倍,而视觉编码器尺度较小3.4倍。 Model的建筑研究人员首先探索了将FastVit Hybrid Vision编码器申请到VLM的潜力,然后提出了一些建筑障碍技术,以提高VLM活动的一般性能。在此基础上,研究人员建议FastVit-HD-A现代混合视觉编码为高分辨率处理活动定制,结合了高效率和高性能。通过大量的消融实验,研究人员与原始的FastVit和在各种大规模语言(LLM)体系结构和各种图像分辨率条件下的原始FASTVIT和现有方法相比,已充分证明了FastVit-HD性能的显着优势。如图2所示,显示了FastVLM和FastVit-HD的一般体系结构。所有实验都使用与LLAVA-1.5相同的训练调整,除非指定,否则使用Vicuna 7b作为语言解码器。 FastVit是一种典型的VLM(如LLAVA),包含三个震惊:图像编码器,视觉语言投影仪和大型语言模型(LLM)。 VLM系统的性能和操作效率高度取决于其视觉脊柱。高分辨率图像的编码对于各种VLM基准活动中的良好性能尤其重要,尤其是在密集文本任务中。因此,支持可扩展分辨率的视觉编码对于VLM尤为重要。研究人员发现,混合视觉编码器(由卷积层和变压器块组成)是VLM的非常微妙的选择,以及支持民间分辨率缩放的对流组件,而变压器模块进一步捕获了LLM的高质量视觉图表。一个Periment用于在剪辑中预先进行交易的混合视觉编码器 - iLeclip电影建议的MCI2编码器。编码器具有3570万参数,以前在Datacompdr数据集中训练,并且该体系结构基于FastVit。本文将编码器称为“ fastvit”。但是,如表1所示,如果仅在预训练的分辨率剪辑(256×256)中使用FastVit,则VLM性能并不完美。 FastVit的主要优点是它在图像分辨率的缩放率方面的效率 - 与贴片大小为14的VIT体系结构相比,其生成的令牌数量低5.2倍。如此大的农作物令牌显着提高了VLM的工作效率,因为变压器解码器的预填充时间和第一个令牌(以前的时间)的输出时间大大降低了。当FastVit输入分辨率扩展到768×768时,构成其的视觉令牌的数量通常会以336×336的vit-l/14在336×336的分辨率中使用,但获得了更好的perfo许多VLM基准测试。尽管两个体系结构形成了相同数量的视觉令牌,但在诸如TextVQA和DOCVQA之类的密集文本活动中,这种性能差距尤为明显。此外,尽管在高分辨率下的代币数量仍然保持平坦,但FastVit的总时间仍然比良好的卷积模块短。 1。多尺度特征通常是卷积或混合动力,通常将计算过程分为4个阶段,每个阶段都包含一个降采样操作。 VLM系统通常使用倒数第二层输出功能,但是从网络的前几层获得的信息通常具有不同的晶粒。经济量表的特征的集成不仅可以提高模型的表达能力,而且可以增强倒数第二层中的高度语义信息。这种设计在发现对象时尤其普遍。研究人员对两个设计方案之间的消融进行了比较从不同阶段转换功能:含义池(AVGPooling)和2D深度卷积。如表2所示,深度段的使用具有更大的性能优势。除多尺度功能外,研究人员还进行了各种连接器设计尝试(请参阅其他材料)(有关详细信息,请参见其他材料)。模型结构对于使用层次骨架,例如Convnext和FastVit的架构特别有效。 FastVit-HD:引入上述改进后,FastVit的参数比VIT-L/14更小。它的表现出色,为8.7次。但是,这些Studys表明,扩大图像编码器的大小有助于增强功能。在混合体系结构中,同时在第3阶段和第4阶段(如维生素所使用的)中同时扩大自我意见层的数量和宽度是很常见的,但是我们发现,只有在FastVit上扩展这些层并不是最好的解决方案(请参见图3,请参见图3。细节),这比Convnext-l速度差。为了防止执行额外的自我刺激层的负担,研究人员在结构中增加了一个额外的阶段,并在此之前添加了一个下采样层。在这种结构中,由自我维修层处理的特征sizethe地图以1/32的比例(与1/16的常见混合模型(如维生素)(例如维生素)相比),MLP的最深层甚至由张量下降到1/64。对于计算密集的LLM解码器,该设计大大降低了图像图像的潜伏期,同时将视觉令牌减少到4倍,从而大大减少了第一个输出(TTFT)输出时间。研究人员将FastVit-HD架构命名为。 FastVit-HD由五个阶段组成。转装器模块在前三个阶段使用,并且在最后两个阶段使用多头自我意识模块。每个阶段的深度设置为[2、12、24、4、2],大小肠道的是[96,192,384,768,1536]。 Convffn模块的MLP扩展比率为4.0。参数的总卷为1251m,是Mobileclip家族中最大的FastVit变体的3.5倍,但它比大多数VIT的主要建筑小。研究人员使用了剪辑的预训练设置,该设置已通过Datacomp-DR-1B进行了预训练,然后在模型上进行了FASTVLM培训。如表3所示,尽管FastVit-HD参数值比VIT-L/14小的2.4倍,并且运行速度快6.9倍,但38个多模式零样本活动的平均性能是可比的。与专门为VLM构建的另一个混合维生素模型相比,FastVit-HD参数体积小于2.7倍,识别速度速度更快5.6倍,并且性能性能更好。该表将多模式FastVit-HD的多模式工作性能与其他经过剪辑训练的层次型骨干网络(例如Convernext-l和XXLAT)的llava-1.5培训结束。虽然FastVit-HD参数卷仅为Convnext-XXL的1/6.8,速度最多为3.3倍,其性能仍然可比。 2。VLM语言解码器的视觉编码器ATSYGENGY,性能和延迟之间的权衡受许多因素的影响。一方面,其整体性能取决于:(1)输入图像的分辨率,(2)输出和质量输出量以及(3)LLM建模功能。另一方面,它的总延迟(尤其是令牌,TTFT的第一次)包括延迟图像编码和LLM预填充时间,这受令牌和LLM标度的数量的影响。由于VLM优化空间的高复杂性,有关视觉编码器繁殖的任何结论都应证明有许多与LLM配对的输入分辨率集。与从经验的角度相比,INWE比较了FastVit-HD的可靠性。研究人员尝试了三个LLM(QWEN2-0.5B/1.5B/7B),并进行了Llava-1.5培训和视觉在各种输入分辨率中调整说明,然后在许多活动中审查结果。结果如图4所示。首先,图4中的帕累托最佳曲线表明,与最佳性能相对应的encoder-llm的组合在固定预算条件下是动态的(例如运行时TTFT)。例如,不建议将高分辨率图像输入配备小型LLM,因为小型模型无法有效使用许多令牌。同时,由于视觉编码延迟,TTFT将增加(有关详细信息,请参见图5)。其次,FastVit-HD Traversal(分辨率,LLM)所形成的最佳帕累托曲线明显优于FastVit-在固定延迟预算下,平均性能改善超过2.5点;在同一目标时机下,它可以加速约3次。值得注意的是,先前的结论表明,基于FastVit的VLM超过了VIT-HD,并且FastVit-HD在t上的t剂量更大明显改善他的基础。 3。调整输入分辨率时静态和动态输入分辨率,有两种技术:(1)直接更改模型的输入分辨率; (2)将图像分为图块块,然后将模型输入设置为瓷砖大小。后者属于“ Anyres”方法,该方法主要用于使VIT处理高分辨率图像。但是,FastVit-HD是为高分辨率效率而设计的,因此我们对这两种方法的效率进行了比较审查。图6显示,如果将输入分辨率直接设置为目标分辨率,则VLM已获得准确性和延迟之间的最佳平衡。动态输入仅在输入分辨率很高(例如1536×1536)时显示出好处,并且瓶颈主要显示在设备上的内存带宽中。使用动态方法时,瓷砖数量越小,可以实现更好的精度 - 性能延迟。以及Har的发展Dware和存储器带宽,FastVLM实现了增加的分辨率处理而无需瓷砖拆分将是一个可行的方向。 4。与代币修剪和下采样方法的比较研究人员更多地比较了FastVit-HD与各种输入分辨率以及经典的Pamperslow代币修剪。如表5所示,使用层次骨干网络的VLM明显优于基于各向同性体系结构的过程,并且在代币修剪的帮助下已经优化。 FastVit-HD可以在不使用修剪方法和仅使用低分辨率训练的情况下将视觉令牌的数量减少到只有16个,并且比最近的一些令牌修剪解决方案更好。有趣的是,尽管最先进的令牌修剪方法(如建议[7,28,29,80]),但总体性能在256×256的分辨率中不如FASTVIT-HD好。有关更多详细信息,请参阅原始论文。
85x速度迷:Apple的开源是FastVLM,这是一种可以直接在iPhone上运行的视觉语言模型
FastVLM-让Apple手机具有非常快速的视觉理解功能。当您使用iPhone拍照并问AI时:“这是什么?”时,它背后的FastVLM模型是悄悄地 - 模型。最近,Apple开设了一个出色的视觉语言模型的来源,该模型可以直接在iPhone -fastvlm(快速视觉语言模型)上运行。代码链接:https://github.com/apple/ml-tastvlm代码存储库包括基于MLX框架的iOS/macOS演示的应用程序,该框架优化了Apple设备上的操作性性能。看到这个演示,是反应速度非常“快速”!这就是使FastVLM与众不同的原因。与传统模型相比,FASTVLM模型着重于解决两个主要卷和速度问题。这比类似的型号快,偏高的输出速度速度高85倍。该模型引入了一个新的混合视觉编码器FastVithD,该编码器结合了卷积层和变压器模块。结合多尺度合并和唐萨姆固定技术,图像处理所需的“视觉令牌”的数量减少到非常低 - 比传统VIT的16倍,比FastVit少4倍。这极大地改善了AI和图像之间的用户体验,并以极高的速度和兼容性。 Ang Modelo ng fastvlm ay印地语lamang maaaring magamit magamit upang awtomatikongakabuo ng mga pahayag para sa Modelo,sagutin ang mga katanungan tungkol sa“ ano ang arn an ang larawang ito?” Madaling Inangkop SA MGA应用程序NG IOS/MAC生态系统,Lalo na ang Angkop para sa mga aparato sa gilid,MGA端端Na Mga aplikasyon ng ai在实时图形和任务方案下。当前,FASTVLM模型主要启动三个不同参数订单的版本:0.5B,1.5B和7B。每个版本都有两个重量的阶段:Stage2和Stage3,并且可以根据自己的需求选择用户。苹果团队详细详细介绍了e具体的技术细节和优化已发表论文的途径。纸张标题:FastVLM:视觉语言纸张地址的出色视觉句子模型:https://www.arxiv.org/abs/2412.13303视觉语言研究模型(VLMS)是一种可以同时了解图像和文本信息的多模型。 VLM通常通过投影层(也已知的BSOME连接模块)将视觉令牌从预先的视觉主链网络转到预先进行的LLM。先前的研究探索了视觉脊柱网络和适配器。这三个组件LLM的训练技术和微调是常见的解码器结构。许多研究教导说,图像分辨率是影响VLM性能的主要因素,尤其是面对密集或密集的图形数据时。但是,改进图像分辨率也带来了许多挑战。首先,许多预先的视力编码器在设计时不支持高分辨率图像输入,因为它的意义远程降低效率。要解决这个问题,一个过程是继续预先对视觉脊柱进行训练,以使其适应高分辨率图像。其余的是图像平铺技术(例如狮身人面像,S2和Anyres)将图像sa除以许多子区域,而视觉脊柱将分别处理每个子区域。这种类型的方法特别适合基于视觉变压器(VIT)的模型体系结构,因为VIT通常不支持变量输入分辨率。另一个挑战来自计算高分辨率高分辨率时计算运行时的成本。无论是对高分辨率的单一概念还是对较低分辨率的多重理解(即使用切口方法),视觉令牌的形成都有很大的延迟。此外,具有高分辨率的图像本身会产生更多的令牌,从而进一步增加了LLM预填充时间(即预填充时间,即LLM促进的时间TS向前计算在包括VisualStoken在内的所有上下文令牌上),从而扩大了一般的初始输出时间(TTTFT,TTFT),即视觉编码器延迟和语言时间预填充的总和。这项研究将VLM设备的部署作为驱动力,并从运行时效率的前景中进行了系统的设计和培训研究。我们专注于改善图像分辨率对优化空间的影响,目的是提高权衡的准确性 - 延迟,其中延迟包括视觉编码器的前景时间和LLM的预填充时间。通过在各种LLM量表和图像分辨率上进行大量实验,研究人员证明,在特定的视觉脊柱条件下,可以建立帕累托的最佳条件,以证明最佳准确度可以通过在有限的运行频率预算(TTTFT)中纳入各种图像分辨率和语言模型来实现。研究人员有FIRT探索了FastVit(Mobileclip预先获得的杂种卷积架构架构)作为VLM视觉脊柱的潜力。实验表明,这种混合脊柱在开发视觉令牌中的速度比标准VIT模型快四倍以上,同时还基于多规模的视觉特征,可以实现VLM提高的总体精度。但是,如果目标是主要的高分辨率VLM(而不是简单地关注作为MobileClip的一代的嵌入),则该体系结构仍将有进一步优化的空间。因此,研究人员提出了一种新的混合视觉编码器FastVithD,旨在在处理高分辨率图像时MAVLM效率提高。它被用作脊柱网络,通过微调视觉说明来获取FASTVLM。 FASTVLM显着优于基于VIT,卷积元素编码器的VLM程序,并且我们先前建议的杂种结构迅速地以精确范围ACY和延迟权衡。特别是,与以最高分辨率(1152×1152)运行的Llava-onevision相比,FASTVLM在0.5B LLM的相同条件下实现了可比的性能,而TTFT的速度更快85倍,而视觉编码器尺度较小3.4倍。 Model的建筑研究人员首先探索了将FastVit Hybrid Vision编码器申请到VLM的潜力,然后提出了一些建筑障碍技术,以提高VLM活动的一般性能。在此基础上,研究人员建议FastVit-HD-A现代混合视觉编码为高分辨率处理活动定制,结合了高效率和高性能。通过大量的消融实验,研究人员与原始的FastVit和在各种大规模语言(LLM)体系结构和各种图像分辨率条件下的原始FASTVIT和现有方法相比,已充分证明了FastVit-HD性能的显着优势。如图2所示,显示了FastVLM和FastVit-HD的一般体系结构。所有实验都使用与LLAVA-1.5相同的训练调整,除非指定,否则使用Vicuna 7b作为语言解码器。 FastVit是一种典型的VLM(如LLAVA),包含三个震惊:图像编码器,视觉语言投影仪和大型语言模型(LLM)。 VLM系统的性能和操作效率高度取决于其视觉脊柱。高分辨率图像的编码对于各种VLM基准活动中的良好性能尤其重要,尤其是在密集文本任务中。因此,支持可扩展分辨率的视觉编码对于VLM尤为重要。研究人员发现,混合视觉编码器(由卷积层和变压器块组成)是VLM的非常微妙的选择,以及支持民间分辨率缩放的对流组件,而变压器模块进一步捕获了LLM的高质量视觉图表。一个Periment用于在剪辑中预先进行交易的混合视觉编码器 - iLeclip电影建议的MCI2编码器。编码器具有3570万参数,以前在Datacompdr数据集中训练,并且该体系结构基于FastVit。本文将编码器称为“ fastvit”。但是,如表1所示,如果仅在预训练的分辨率剪辑(256×256)中使用FastVit,则VLM性能并不完美。 FastVit的主要优点是它在图像分辨率的缩放率方面的效率 - 与贴片大小为14的VIT体系结构相比,其生成的令牌数量低5.2倍。如此大的农作物令牌显着提高了VLM的工作效率,因为变压器解码器的预填充时间和第一个令牌(以前的时间)的输出时间大大降低了。当FastVit输入分辨率扩展到768×768时,构成其的视觉令牌的数量通常会以336×336的vit-l/14在336×336的分辨率中使用,但获得了更好的perfo许多VLM基准测试。尽管两个体系结构形成了相同数量的视觉令牌,但在诸如TextVQA和DOCVQA之类的密集文本活动中,这种性能差距尤为明显。此外,尽管在高分辨率下的代币数量仍然保持平坦,但FastVit的总时间仍然比良好的卷积模块短。 1。多尺度特征通常是卷积或混合动力,通常将计算过程分为4个阶段,每个阶段都包含一个降采样操作。 VLM系统通常使用倒数第二层输出功能,但是从网络的前几层获得的信息通常具有不同的晶粒。经济量表的特征的集成不仅可以提高模型的表达能力,而且可以增强倒数第二层中的高度语义信息。这种设计在发现对象时尤其普遍。研究人员对两个设计方案之间的消融进行了比较从不同阶段转换功能:含义池(AVGPooling)和2D深度卷积。如表2所示,深度段的使用具有更大的性能优势。除多尺度功能外,研究人员还进行了各种连接器设计尝试(请参阅其他材料)(有关详细信息,请参见其他材料)。模型结构对于使用层次骨架,例如Convnext和FastVit的架构特别有效。 FastVit-HD:引入上述改进后,FastVit的参数比VIT-L/14更小。它的表现出色,为8.7次。但是,这些Studys表明,扩大图像编码器的大小有助于增强功能。在混合体系结构中,同时在第3阶段和第4阶段(如维生素所使用的)中同时扩大自我意见层的数量和宽度是很常见的,但是我们发现,只有在FastVit上扩展这些层并不是最好的解决方案(请参见图3,请参见图3。细节),这比Convnext-l速度差。为了防止执行额外的自我刺激层的负担,研究人员在结构中增加了一个额外的阶段,并在此之前添加了一个下采样层。在这种结构中,由自我维修层处理的特征sizethe地图以1/32的比例(与1/16的常见混合模型(如维生素)(例如维生素)相比),MLP的最深层甚至由张量下降到1/64。对于计算密集的LLM解码器,该设计大大降低了图像图像的潜伏期,同时将视觉令牌减少到4倍,从而大大减少了第一个输出(TTFT)输出时间。研究人员将FastVit-HD架构命名为。 FastVit-HD由五个阶段组成。转装器模块在前三个阶段使用,并且在最后两个阶段使用多头自我意识模块。每个阶段的深度设置为[2、12、24、4、2],大小肠道的是[96,192,384,768,1536]。 Convffn模块的MLP扩展比率为4.0。参数的总卷为1251m,是Mobileclip家族中最大的FastVit变体的3.5倍,但它比大多数VIT的主要建筑小。研究人员使用了剪辑的预训练设置,该设置已通过Datacomp-DR-1B进行了预训练,然后在模型上进行了FASTVLM培训。如表3所示,尽管FastVit-HD参数值比VIT-L/14小的2.4倍,并且运行速度快6.9倍,但38个多模式零样本活动的平均性能是可比的。与专门为VLM构建的另一个混合维生素模型相比,FastVit-HD参数体积小于2.7倍,识别速度速度更快5.6倍,并且性能性能更好。该表将多模式FastVit-HD的多模式工作性能与其他经过剪辑训练的层次型骨干网络(例如Convernext-l和XXLAT)的llava-1.5培训结束。虽然FastVit-HD参数卷仅为Convnext-XXL的1/6.8,速度最多为3.3倍,其性能仍然可比。 2。VLM语言解码器的视觉编码器ATSYGENGY,性能和延迟之间的权衡受许多因素的影响。一方面,其整体性能取决于:(1)输入图像的分辨率,(2)输出和质量输出量以及(3)LLM建模功能。另一方面,它的总延迟(尤其是令牌,TTFT的第一次)包括延迟图像编码和LLM预填充时间,这受令牌和LLM标度的数量的影响。由于VLM优化空间的高复杂性,有关视觉编码器繁殖的任何结论都应证明有许多与LLM配对的输入分辨率集。与从经验的角度相比,INWE比较了FastVit-HD的可靠性。研究人员尝试了三个LLM(QWEN2-0.5B/1.5B/7B),并进行了Llava-1.5培训和视觉在各种输入分辨率中调整说明,然后在许多活动中审查结果。结果如图4所示。首先,图4中的帕累托最佳曲线表明,与最佳性能相对应的encoder-llm的组合在固定预算条件下是动态的(例如运行时TTFT)。例如,不建议将高分辨率图像输入配备小型LLM,因为小型模型无法有效使用许多令牌。同时,由于视觉编码延迟,TTFT将增加(有关详细信息,请参见图5)。其次,FastVit-HD Traversal(分辨率,LLM)所形成的最佳帕累托曲线明显优于FastVit-在固定延迟预算下,平均性能改善超过2.5点;在同一目标时机下,它可以加速约3次。值得注意的是,先前的结论表明,基于FastVit的VLM超过了VIT-HD,并且FastVit-HD在t上的t剂量更大明显改善他的基础。 3。调整输入分辨率时静态和动态输入分辨率,有两种技术:(1)直接更改模型的输入分辨率; (2)将图像分为图块块,然后将模型输入设置为瓷砖大小。后者属于“ Anyres”方法,该方法主要用于使VIT处理高分辨率图像。但是,FastVit-HD是为高分辨率效率而设计的,因此我们对这两种方法的效率进行了比较审查。图6显示,如果将输入分辨率直接设置为目标分辨率,则VLM已获得准确性和延迟之间的最佳平衡。动态输入仅在输入分辨率很高(例如1536×1536)时显示出好处,并且瓶颈主要显示在设备上的内存带宽中。使用动态方法时,瓷砖数量越小,可以实现更好的精度 - 性能延迟。以及Har的发展Dware和存储器带宽,FastVLM实现了增加的分辨率处理而无需瓷砖拆分将是一个可行的方向。 4。与代币修剪和下采样方法的比较研究人员更多地比较了FastVit-HD与各种输入分辨率以及经典的Pamperslow代币修剪。如表5所示,使用层次骨干网络的VLM明显优于基于各向同性体系结构的过程,并且在代币修剪的帮助下已经优化。 FastVit-HD可以在不使用修剪方法和仅使用低分辨率训练的情况下将视觉令牌的数量减少到只有16个,并且比最近的一些令牌修剪解决方案更好。有趣的是,尽管最先进的令牌修剪方法(如建议[7,28,29,80]),但总体性能在256×256的分辨率中不如FASTVIT-HD好。有关更多详细信息,请参阅原始论文。
