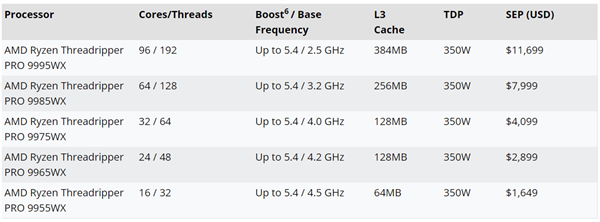
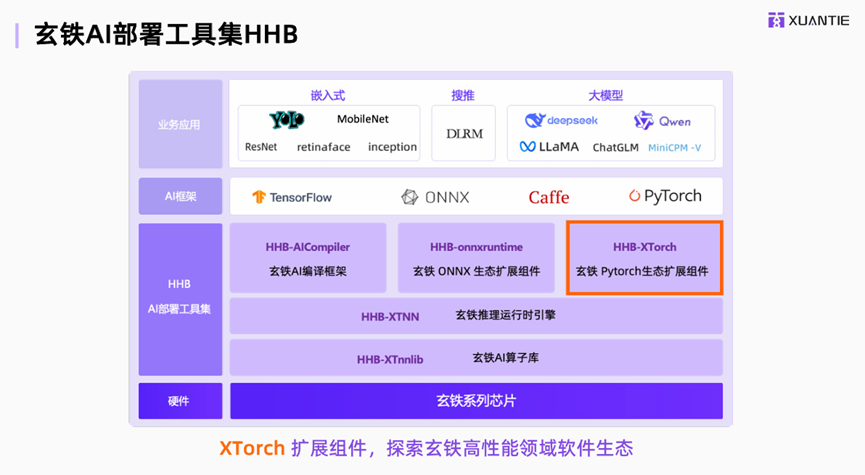
 7дТ18ШеЃЌЕк5НьRISC-VжаЙњЗхЛсВЮМгСЫЩЯКЃЕФДЮМЖПЮГЬЁЃзїЮЊЮДРДЕчзгаавЕЕФзюДѓгІгУСьгђжЎвЛЃЌШЫЙЄжЧФмЪЧВЛПЩБмУтЕФЛАЬтЁЃШЫЙЄжЧФмЕФПьЫйЗЂеЙЭЦЖЏСЫЛљДЁНЈжўЕФБфЛЏЃЌМЦЫуЧПЖШашЧѓЕФЦНОљФъдіГЄТЪГЌЙ§100ЃЅЁЃ ЁАПЊЗХЃЌСщЛюКЭПЩЖЈжЦЕФЁБ RISC-VвбГЩЮЊЗЂеЙAIМЦЫуЖРСЂСІСПЕФЛљДЁЕФеНТджЇЕуЁЃШЫЙЄзгВПбћЧыИїЗНЕФЙЋЫОЬжТлRISC-VМмЙЙШчКЮЪЙгУПЊЗХзЪдДЃЌПЊЗХКЭВтСПЕФЙІФмРДЪЕЯжAIМЦЫуЬхЯЕНсЙЙЕФБфЛЏЃЌвдМАAIШэМўКЭHardwareжаRISC-VМмЙЙгІгУГЬађЕФзюаТПЊЗЂКЭЪЕЪЉЁЃАЂРяАЭАЭИУЫРбЇдКЕФИпМЖПЊЗЂЙЄГЬЪІаьХэЃЈXu PengЃЉЗжЯэСЫИУЕиЧјВПЪ№КЭгХЛЏXuantie AIДѓаЭФЃаЭЕФММЧЩЁЃзїЮЊЗЂеЙИпМЖЕФЯШЧ§XuantenЭХЖгдкжаЙњЕФPerformance RISC-VДІРэЦїIPвЛжБСьЕМЙњФкRISC-VЕФНЈжўБпНчЃЌвдAIгІгУРЉеЙММЪѕЁЃ Xu PengЬсГіЃЌЕН2025Фъ3дТЕзЃЌЁА MaopaЩчЧјЁБПЊЗХзЪдДЕФЪ§СПГЌЙ§52,000ЃЌгыДЫЭЌЪБЃЌЁА QianwenФЃаЭМвзхЁБМАЦфбмЩњаЭКХГЌЙ§100,000ЁЃВЛНіДЋЭГФЃаЭЕФЪ§СПКмДѓЃЌЖјЧвДѓаЭФЃаЭвВГіЯждкВЛЭЌЕФаавЕКЭаавЕжаЁЃ Xuantieе§дкЛ§МЋДйНјЯђСПКЭAMEЁЃФПЧАЃЌRISC-VЩчЧјЕФЕБЧАЯђСПвбОзМБИОЭаїЃЌAMEвВе§дкПьЫйвЦЖЏЁЃЛљгкЩЯЪівЕЮёКЭИќаТжаЕФвЛВПЗжЃЌЖдЩЯВПШэМўЖбеЛЬсГіСЫИќИпЕФвЊЧѓЁЃЬиБ№ЪЧЖдгкAIЕФXuantennДІРэЦїЙІФмЕФЗЂеЙЃЌXuantenдк2019ФъГѕПЊЪМжДааЪИСП0.7.1ЃЌЦфДЮЪЧЯђСП1.0ЃЌШЛКѓЪЧОоДѓЕФPytorchesКЭAMEЕЅЮЛЁЃзюНќЃЌXuantenИќаТСЫЕкЖўДњAMEЕЅЮЛЁЃ XuantieгВМўе§дкВЛЖЯИќИФPytorchКЭAMEЕЅдЊЃЌЬсИпМЦЫуФмСІЃЌдіМгЪ§ОнРраЭжЇГжЃЌМгЫйЬиЪтВйзївдМАеыЖдLLMЗНАИЕФгаеыЖдаддіЧПЁЃЯТЭМЯдЪОСЫгыXuantieКЭгВМўЩњЬЌЯЕЭГгаЙиЕФвЕЮёашЧѓЃЌXuantie AIВПЪ№ЙЄОпМЏHHBЁЃ Xuantie AIЕФЙЄОпМЏАќРЈШ§ИіМЖБ№ЃЌАќРЈHHB AICompilerЃЌHHB InnxRuntimeКЭHHB-OrtorchЁЃ XuantieЕФСэвЛИіживЊШЮЮёЪЧPytorchРЉеЙЁЃЮЊСЫЮЊPytorchЬсЙЉСМКУЕФжЇГжЃЌвЛЗНУцЃЌгУЛЇПЩвддкУЛгаЭДПрЕФЧщПіЯТЧаЛЛЕНRISC-VгВМўЃЌСэвЛЗНУцЃЌЫћУЧПЩвджиИДЪЙгУPytorchЕБЧАГЩЪьЕФЩњЬЌЯЕЭГЩњЬЌЯЕЭГВЂРЉеЙRISC-VЕФAIЙІФмЁЃЬиБ№ЪЧдкXtorchжаЃЌXtorchЮЊДѓаЭаЭКХКЭMOEФЃаЭЬсЙЉСЫвЛИіШкКЯВйзїдБЯЕСаЃЌЖЫЕНЖЫЕФадФмЬсИпСЫ11.2ЃЅЁЃЭЌЪБЃЌдкДЫМЖБ№ЕФгУЛЇВПЪ№вВКмЗНБуЃЌЬсЙЉСЫвЛаЉЛљБОЫуЗЈЃЌВЂОпгаГіЩЋЕФcapabilitIESгУгкДѓаЭаЭКХЁЃЪОР§ЃКAWQЃЌGPTQЕШЃЌЛЙЬсЙЉСЫжюШчQ80жЎРрЕФЖрВуДЮКЭЖрОЋШЗЪ§СПЙІФмЁЃШУЮвУЧПДПДXtorchШчКЮМгЫйДѓЙцФЃЭЦРэЁЃЯТЭМзїЮЊЕфаЭЕФЭМЁЃ OrmerЗЖЪННјааДѓЙцФЃЭЦРэЁЃдкзюМђЕЅЕФЙ§ГЬжаЃЌЮвУЧжЛашвЊЪфШыСНааДњТыМДПЩЦєгУXTORCHМДПЩДяЕНPytorchзюМгЫйЕФМгЫйЖШЁЃгвБпЪЧXtorchжаЕФвЛаЉЙЄзїЃЌР§ШчMOEЕФВйзїдБШкКЯЃЌвдМАЦфЫћвЛаЉГЃЙцЕФШкКЯВйзїдБКЭФЃаЭгХЛЏЙІФмЁЃЕкШ§ИіЙЄзїПЊЗЂЪЧКкЬњдЫааЪБв§ЧцКЭКкЬњВйзїдБЭМЪщЙнЁЃ Xuan Iron NNПтжЇГжЖдОВЬЌКЭЖЏЬЌЭМЕФРэНтЃЌВЂжЇГжаэЖрРраЭЕФЪ§ОнКЭаТРраЭЕФЪ§ОнЃЈР§ШчFP8КЭFP4ЃЉЕФРэНтЃЌетаЉЪ§ОнашвЊдкЕБЧАЕФДѓаЭФЃаЭжаЪЙгУЁЃМЦЫуЙЄзїНјШыXuantennЕФNNВйзїКѓЃЌећИіМЦЫуШЮЮёНЋвЛвЛЛЎЗжЮЊВйзїЃЌвджДааЪЪгУгкЕЅИіКЫаФВйзїЕФВйзїЁЃ XuananenЬсЙЉСЫТнЮЦжЎМфЕФИКдиИКдиЃЌвдПЊЗЂзюжеЕФЖрКЫЧжжЦЁЃЭЌЪБЃЌдкРэНтДѓаЭФЃаЭЕФЙ§ГЬжаЃЌXuan TieНЋЭЈЙ§ФЃаЭЕФЕЅИіДѓаЭМЦЫуФЃаЭзїЮЊЯрЭЌЕФМЦЫуСїГЬНјааДІРэЃЌШЛКѓЭЈЙ§ШЋЧђМьВщећИіМЦЫуСїСПЕФМьВщЃЌВЂаадЫаагВМўЕФФмСІНЋзюДѓЛЏЃЌВЂЭЈЙ§ЭМНЋЭъГЩадФмЬсИпСЫ20.5ЃЅЁЃЛљДЁВуЪЧСїЪ§ОнЕЅдЊжаЕФГщЯѓОиеѓКЭЯђСПЃЌВЂЭЌЪБЕїећЫљгаМЦЫуКЭЭЈаХЛюЖЏЃЌетПЩвдМѕЩйгВМўЕШД§ЪБМфЃЌЖјВЛЪЧДЋЭГЪЕЪЉЗНЗЈЁЃ XuantieЭХЖгЕФгХЪЦПЩвджДаааЕїЕФШэМўКЭгВМўгХЛЏЃЌВЂЧвПЩвддкВЂааЙІФмжаЪЙгУРДМгЫйSoftMaxМЦЫуЁЃгВМўНЋИљОнТњзуашЧѓЃЌВЂзюжеПЊЗЂСЫвЛЯЕСаDUPЕФЫЕУїЃЌетаЉЫЕУїзюжеНЋЗЂеЙГіШэаЇЙћЃЌВЂЭЈЙ§БеЛЗМгЫйЖШдіМг8БЖЁЃдкЪИСПЗНУцЃЌДѓаЭФЃаЭжаЪЙгУЕФЛАгяНЋЪЙгУSigmoidКЭЙЪеЯВйзїЃЌЖјКкЩЋИжжЦгВМўНЋзЈУХДДНЈВйзїЫйЖШЁЃР§ШчЃЌSigmoidКЭSiluВйзїдБНЋИФЩЦ5БЖЁЃгыFP16КЭОКељЖдЪжЯрБШЃЌМгЫйЖШЕФаЇЙћМИКѕИп3БЖЁЃ
7дТ18ШеЃЌЕк5НьRISC-VжаЙњЗхЛсВЮМгСЫЩЯКЃЕФДЮМЖПЮГЬЁЃзїЮЊЮДРДЕчзгаавЕЕФзюДѓгІгУСьгђжЎвЛЃЌШЫЙЄжЧФмЪЧВЛПЩБмУтЕФЛАЬтЁЃШЫЙЄжЧФмЕФПьЫйЗЂеЙЭЦЖЏСЫЛљДЁНЈжўЕФБфЛЏЃЌМЦЫуЧПЖШашЧѓЕФЦНОљФъдіГЄТЪГЌЙ§100ЃЅЁЃ ЁАПЊЗХЃЌСщЛюКЭПЩЖЈжЦЕФЁБ RISC-VвбГЩЮЊЗЂеЙAIМЦЫуЖРСЂСІСПЕФЛљДЁЕФеНТджЇЕуЁЃШЫЙЄзгВПбћЧыИїЗНЕФЙЋЫОЬжТлRISC-VМмЙЙШчКЮЪЙгУПЊЗХзЪдДЃЌПЊЗХКЭВтСПЕФЙІФмРДЪЕЯжAIМЦЫуЬхЯЕНсЙЙЕФБфЛЏЃЌвдМАAIШэМўКЭHardwareжаRISC-VМмЙЙгІгУГЬађЕФзюаТПЊЗЂКЭЪЕЪЉЁЃАЂРяАЭАЭИУЫРбЇдКЕФИпМЖПЊЗЂЙЄГЬЪІаьХэЃЈXu PengЃЉЗжЯэСЫИУЕиЧјВПЪ№КЭгХЛЏXuantie AIДѓаЭФЃаЭЕФММЧЩЁЃзїЮЊЗЂеЙИпМЖЕФЯШЧ§XuantenЭХЖгдкжаЙњЕФPerformance RISC-VДІРэЦїIPвЛжБСьЕМЙњФкRISC-VЕФНЈжўБпНчЃЌвдAIгІгУРЉеЙММЪѕЁЃ Xu PengЬсГіЃЌЕН2025Фъ3дТЕзЃЌЁА MaopaЩчЧјЁБПЊЗХзЪдДЕФЪ§СПГЌЙ§52,000ЃЌгыДЫЭЌЪБЃЌЁА QianwenФЃаЭМвзхЁБМАЦфбмЩњаЭКХГЌЙ§100,000ЁЃВЛНіДЋЭГФЃаЭЕФЪ§СПКмДѓЃЌЖјЧвДѓаЭФЃаЭвВГіЯждкВЛЭЌЕФаавЕКЭаавЕжаЁЃ Xuantieе§дкЛ§МЋДйНјЯђСПКЭAMEЁЃФПЧАЃЌRISC-VЩчЧјЕФЕБЧАЯђСПвбОзМБИОЭаїЃЌAMEвВе§дкПьЫйвЦЖЏЁЃЛљгкЩЯЪівЕЮёКЭИќаТжаЕФвЛВПЗжЃЌЖдЩЯВПШэМўЖбеЛЬсГіСЫИќИпЕФвЊЧѓЁЃЬиБ№ЪЧЖдгкAIЕФXuantennДІРэЦїЙІФмЕФЗЂеЙЃЌXuantenдк2019ФъГѕПЊЪМжДааЪИСП0.7.1ЃЌЦфДЮЪЧЯђСП1.0ЃЌШЛКѓЪЧОоДѓЕФPytorchesКЭAMEЕЅЮЛЁЃзюНќЃЌXuantenИќаТСЫЕкЖўДњAMEЕЅЮЛЁЃ XuantieгВМўе§дкВЛЖЯИќИФPytorchКЭAMEЕЅдЊЃЌЬсИпМЦЫуФмСІЃЌдіМгЪ§ОнРраЭжЇГжЃЌМгЫйЬиЪтВйзївдМАеыЖдLLMЗНАИЕФгаеыЖдаддіЧПЁЃЯТЭМЯдЪОСЫгыXuantieКЭгВМўЩњЬЌЯЕЭГгаЙиЕФвЕЮёашЧѓЃЌXuantie AIВПЪ№ЙЄОпМЏHHBЁЃ Xuantie AIЕФЙЄОпМЏАќРЈШ§ИіМЖБ№ЃЌАќРЈHHB AICompilerЃЌHHB InnxRuntimeКЭHHB-OrtorchЁЃ XuantieЕФСэвЛИіживЊШЮЮёЪЧPytorchРЉеЙЁЃЮЊСЫЮЊPytorchЬсЙЉСМКУЕФжЇГжЃЌвЛЗНУцЃЌгУЛЇПЩвддкУЛгаЭДПрЕФЧщПіЯТЧаЛЛЕНRISC-VгВМўЃЌСэвЛЗНУцЃЌЫћУЧПЩвджиИДЪЙгУPytorchЕБЧАГЩЪьЕФЩњЬЌЯЕЭГЩњЬЌЯЕЭГВЂРЉеЙRISC-VЕФAIЙІФмЁЃЬиБ№ЪЧдкXtorchжаЃЌXtorchЮЊДѓаЭаЭКХКЭMOEФЃаЭЬсЙЉСЫвЛИіШкКЯВйзїдБЯЕСаЃЌЖЫЕНЖЫЕФадФмЬсИпСЫ11.2ЃЅЁЃЭЌЪБЃЌдкДЫМЖБ№ЕФгУЛЇВПЪ№вВКмЗНБуЃЌЬсЙЉСЫвЛаЉЛљБОЫуЗЈЃЌВЂОпгаГіЩЋЕФcapabilitIESгУгкДѓаЭаЭКХЁЃЪОР§ЃКAWQЃЌGPTQЕШЃЌЛЙЬсЙЉСЫжюШчQ80жЎРрЕФЖрВуДЮКЭЖрОЋШЗЪ§СПЙІФмЁЃШУЮвУЧПДПДXtorchШчКЮМгЫйДѓЙцФЃЭЦРэЁЃЯТЭМзїЮЊЕфаЭЕФЭМЁЃ OrmerЗЖЪННјааДѓЙцФЃЭЦРэЁЃдкзюМђЕЅЕФЙ§ГЬжаЃЌЮвУЧжЛашвЊЪфШыСНааДњТыМДПЩЦєгУXTORCHМДПЩДяЕНPytorchзюМгЫйЕФМгЫйЖШЁЃгвБпЪЧXtorchжаЕФвЛаЉЙЄзїЃЌР§ШчMOEЕФВйзїдБШкКЯЃЌвдМАЦфЫћвЛаЉГЃЙцЕФШкКЯВйзїдБКЭФЃаЭгХЛЏЙІФмЁЃЕкШ§ИіЙЄзїПЊЗЂЪЧКкЬњдЫааЪБв§ЧцКЭКкЬњВйзїдБЭМЪщЙнЁЃ Xuan Iron NNПтжЇГжЖдОВЬЌКЭЖЏЬЌЭМЕФРэНтЃЌВЂжЇГжаэЖрРраЭЕФЪ§ОнКЭаТРраЭЕФЪ§ОнЃЈР§ШчFP8КЭFP4ЃЉЕФРэНтЃЌетаЉЪ§ОнашвЊдкЕБЧАЕФДѓаЭФЃаЭжаЪЙгУЁЃМЦЫуЙЄзїНјШыXuantennЕФNNВйзїКѓЃЌећИіМЦЫуШЮЮёНЋвЛвЛЛЎЗжЮЊВйзїЃЌвджДааЪЪгУгкЕЅИіКЫаФВйзїЕФВйзїЁЃ XuananenЬсЙЉСЫТнЮЦжЎМфЕФИКдиИКдиЃЌвдПЊЗЂзюжеЕФЖрКЫЧжжЦЁЃЭЌЪБЃЌдкРэНтДѓаЭФЃаЭЕФЙ§ГЬжаЃЌXuan TieНЋЭЈЙ§ФЃаЭЕФЕЅИіДѓаЭМЦЫуФЃаЭзїЮЊЯрЭЌЕФМЦЫуСїГЬНјааДІРэЃЌШЛКѓЭЈЙ§ШЋЧђМьВщећИіМЦЫуСїСПЕФМьВщЃЌВЂаадЫаагВМўЕФФмСІНЋзюДѓЛЏЃЌВЂЭЈЙ§ЭМНЋЭъГЩадФмЬсИпСЫ20.5ЃЅЁЃЛљДЁВуЪЧСїЪ§ОнЕЅдЊжаЕФГщЯѓОиеѓКЭЯђСПЃЌВЂЭЌЪБЕїећЫљгаМЦЫуКЭЭЈаХЛюЖЏЃЌетПЩвдМѕЩйгВМўЕШД§ЪБМфЃЌЖјВЛЪЧДЋЭГЪЕЪЉЗНЗЈЁЃ XuantieЭХЖгЕФгХЪЦПЩвджДаааЕїЕФШэМўКЭгВМўгХЛЏЃЌВЂЧвПЩвддкВЂааЙІФмжаЪЙгУРДМгЫйSoftMaxМЦЫуЁЃгВМўНЋИљОнТњзуашЧѓЃЌВЂзюжеПЊЗЂСЫвЛЯЕСаDUPЕФЫЕУїЃЌетаЉЫЕУїзюжеНЋЗЂеЙГіШэаЇЙћЃЌВЂЭЈЙ§БеЛЗМгЫйЖШдіМг8БЖЁЃдкЪИСПЗНУцЃЌДѓаЭФЃаЭжаЪЙгУЕФЛАгяНЋЪЙгУSigmoidКЭЙЪеЯВйзїЃЌЖјКкЩЋИжжЦгВМўНЋзЈУХДДНЈВйзїЫйЖШЁЃР§ШчЃЌSigmoidКЭSiluВйзїдБНЋИФЩЦ5БЖЁЃгыFP16КЭОКељЖдЪжЯрБШЃЌМгЫйЖШЕФаЇЙћМИКѕИп3БЖЁЃ
ЛљгкRiscЕФChinite
7дТ18ШеЃЌЕк5НьRISC-VжаЙњЗхЛсВЮМгСЫЩЯКЃЕФДЮМЖПЮГЬЁЃзїЮЊЮДРДЕчзгаавЕЕФзюДѓгІгУСьгђжЎвЛЃЌШЫЙЄжЧФмЪЧВЛПЩБмУтЕФЛАЬтЁЃШЫЙЄжЧФмЕФПьЫйЗЂеЙЭЦЖЏСЫЛљДЁНЈжўЕФБфЛЏЃЌМЦЫуЧПЖШашЧѓЕФЦНОљФъдіГЄТЪГЌЙ§100ЃЅЁЃ ЁАПЊЗХЃЌСщЛюКЭПЩЖЈжЦЕФЁБ RISC-VвбГЩЮЊЗЂеЙAIМЦЫуЖРСЂСІСПЕФЛљДЁЕФеНТджЇЕуЁЃШЫЙЄзгВПбћЧыИїЗНЕФЙЋЫОЬжТлRISC-VМмЙЙШчКЮЪЙгУПЊЗХзЪдДЃЌПЊЗХКЭВтСПЕФЙІФмРДЪЕЯжAIМЦЫуЬхЯЕНсЙЙЕФБфЛЏЃЌвдМАAIШэМўКЭHardwareжаRISC-VМмЙЙгІгУГЬађЕФзюаТПЊЗЂКЭЪЕЪЉЁЃАЂРяАЭАЭИУЫРбЇдКЕФИпМЖПЊЗЂЙЄГЬЪІаьХэЃЈXu PengЃЉЗжЯэСЫИУЕиЧјВПЪ№КЭгХЛЏXuantie AIДѓаЭФЃаЭЕФММЧЩЁЃзїЮЊЗЂеЙИпМЖЕФЯШЧ§XuantenЭХЖгдкжаЙњЕФPerformance RISC-VДІРэЦїIPвЛжБСьЕМЙњФкRISC-VЕФНЈжўБпНчЃЌвдAIгІгУРЉеЙММЪѕЁЃ Xu PengЬсГіЃЌЕН2025Фъ3дТЕзЃЌЁА MaopaЩчЧјЁБПЊЗХзЪдДЕФЪ§СПГЌЙ§52,000ЃЌгыДЫЭЌЪБЃЌЁА QianwenФЃаЭМвзхЁБМАЦфбмЩњаЭКХГЌЙ§100,000ЁЃВЛНіДЋЭГФЃаЭЕФЪ§СПКмДѓЃЌЖјЧвДѓаЭФЃаЭвВГіЯждкВЛЭЌЕФаавЕКЭаавЕжаЁЃ Xuantieе§дкЛ§МЋДйНјЯђСПКЭAMEЁЃФПЧАЃЌRISC-VЩчЧјЕФЕБЧАЯђСПвбОзМБИОЭаїЃЌAMEвВе§дкПьЫйвЦЖЏЁЃЛљгкЩЯЪівЕЮёКЭИќаТжаЕФвЛВПЗжЃЌЖдЩЯВПШэМўЖбеЛЬсГіСЫИќИпЕФвЊЧѓЁЃЬиБ№ЪЧЖдгкAIЕФXuantennДІРэЦїЙІФмЕФЗЂеЙЃЌXuantenдк2019ФъГѕПЊЪМжДааЪИСП0.7.1ЃЌЦфДЮЪЧЯђСП1.0ЃЌШЛКѓЪЧОоДѓЕФPytorchesКЭAMEЕЅЮЛЁЃзюНќЃЌXuantenИќаТСЫЕкЖўДњAMEЕЅЮЛЁЃ XuantieгВМўе§дкВЛЖЯИќИФPytorchКЭAMEЕЅдЊЃЌЬсИпМЦЫуФмСІЃЌдіМгЪ§ОнРраЭжЇГжЃЌМгЫйЬиЪтВйзївдМАеыЖдLLMЗНАИЕФгаеыЖдаддіЧПЁЃЯТЭМЯдЪОСЫгыXuantieКЭгВМўЩњЬЌЯЕЭГгаЙиЕФвЕЮёашЧѓЃЌXuantie AIВПЪ№ЙЄОпМЏHHBЁЃ Xuantie AIЕФЙЄОпМЏАќРЈШ§ИіМЖБ№ЃЌАќРЈHHB AICompilerЃЌHHB InnxRuntimeКЭHHB-OrtorchЁЃ XuantieЕФСэвЛИіживЊШЮЮёЪЧPytorchРЉеЙЁЃЮЊСЫЮЊPytorchЬсЙЉСМКУЕФжЇГжЃЌвЛЗНУцЃЌгУЛЇПЩвддкУЛгаЭДПрЕФЧщПіЯТЧаЛЛЕНRISC-VгВМўЃЌСэвЛЗНУцЃЌЫћУЧПЩвджиИДЪЙгУPytorchЕБЧАГЩЪьЕФЩњЬЌЯЕЭГЩњЬЌЯЕЭГВЂРЉеЙRISC-VЕФAIЙІФмЁЃЬиБ№ЪЧдкXtorchжаЃЌXtorchЮЊДѓаЭаЭКХКЭMOEФЃаЭЬсЙЉСЫвЛИіШкКЯВйзїдБЯЕСаЃЌЖЫЕНЖЫЕФадФмЬсИпСЫ11.2ЃЅЁЃЭЌЪБЃЌдкДЫМЖБ№ЕФгУЛЇВПЪ№вВКмЗНБуЃЌЬсЙЉСЫвЛаЉЛљБОЫуЗЈЃЌВЂОпгаГіЩЋЕФcapabilitIESгУгкДѓаЭаЭКХЁЃЪОР§ЃКAWQЃЌGPTQЕШЃЌЛЙЬсЙЉСЫжюШчQ80жЎРрЕФЖрВуДЮКЭЖрОЋШЗЪ§СПЙІФмЁЃШУЮвУЧПДПДXtorchШчКЮМгЫйДѓЙцФЃЭЦРэЁЃЯТЭМзїЮЊЕфаЭЕФЭМЁЃ OrmerЗЖЪННјааДѓЙцФЃЭЦРэЁЃдкзюМђЕЅЕФЙ§ГЬжаЃЌЮвУЧжЛашвЊЪфШыСНааДњТыМДПЩЦєгУXTORCHМДПЩДяЕНPytorchзюМгЫйЕФМгЫйЖШЁЃгвБпЪЧXtorchжаЕФвЛаЉЙЄзїЃЌР§ШчMOEЕФВйзїдБШкКЯЃЌвдМАЦфЫћвЛаЉГЃЙцЕФШкКЯВйзїдБКЭФЃаЭгХЛЏЙІФмЁЃЕкШ§ИіЙЄзїПЊЗЂЪЧКкЬњдЫааЪБв§ЧцКЭКкЬњВйзїдБЭМЪщЙнЁЃ Xuan Iron NNПтжЇГжЖдОВЬЌКЭЖЏЬЌЭМЕФРэНтЃЌВЂжЇГжаэЖрРраЭЕФЪ§ОнКЭаТРраЭЕФЪ§ОнЃЈР§ШчFP8КЭFP4ЃЉЕФРэНтЃЌетаЉЪ§ОнашвЊдкЕБЧАЕФДѓаЭФЃаЭжаЪЙгУЁЃМЦЫуЙЄзїНјШыXuantennЕФNNВйзїКѓЃЌећИіМЦЫуШЮЮёНЋвЛвЛЛЎЗжЮЊВйзїЃЌвджДааЪЪгУгкЕЅИіКЫаФВйзїЕФВйзїЁЃ XuananenЬсЙЉСЫТнЮЦжЎМфЕФИКдиИКдиЃЌвдПЊЗЂзюжеЕФЖрКЫЧжжЦЁЃЭЌЪБЃЌдкРэНтДѓаЭФЃаЭЕФЙ§ГЬжаЃЌXuan TieНЋЭЈЙ§ФЃаЭЕФЕЅИіДѓаЭМЦЫуФЃаЭзїЮЊЯрЭЌЕФМЦЫуСїГЬНјааДІРэЃЌШЛКѓЭЈЙ§ШЋЧђМьВщећИіМЦЫуСїСПЕФМьВщЃЌВЂаадЫаагВМўЕФФмСІНЋзюДѓЛЏЃЌВЂЭЈЙ§ЭМНЋЭъГЩадФмЬсИпСЫ20.5ЃЅЁЃЛљДЁВуЪЧСїЪ§ОнЕЅдЊжаЕФГщЯѓОиеѓКЭЯђСПЃЌВЂЭЌЪБЕїећЫљгаМЦЫуКЭЭЈаХЛюЖЏЃЌетПЩвдМѕЩйгВМўЕШД§ЪБМфЃЌЖјВЛЪЧДЋЭГЪЕЪЉЗНЗЈЁЃ XuantieЭХЖгЕФгХЪЦПЩвджДаааЕїЕФШэМўКЭгВМўгХЛЏЃЌВЂЧвПЩвддкВЂааЙІФмжаЪЙгУРДМгЫйSoftMaxМЦЫуЁЃгВМўНЋИљОнТњзуашЧѓЃЌВЂзюжеПЊЗЂСЫвЛЯЕСаDUPЕФЫЕУїЃЌетаЉЫЕУїзюжеНЋЗЂеЙГіШэаЇЙћЃЌВЂЭЈЙ§БеЛЗМгЫйЖШдіМг8БЖЁЃдкЪИСПЗНУцЃЌДѓаЭФЃаЭжаЪЙгУЕФЛАгяНЋЪЙгУSigmoidКЭЙЪеЯВйзїЃЌЖјКкЩЋИжжЦгВМўНЋзЈУХДДНЈВйзїЫйЖШЁЃР§ШчЃЌSigmoidКЭSiluВйзїдБНЋИФЩЦ5БЖЁЃгыFP16КЭОКељЖдЪжЯрБШЃЌМгЫйЖШЕФаЇЙћМИКѕИп3БЖЁЃ